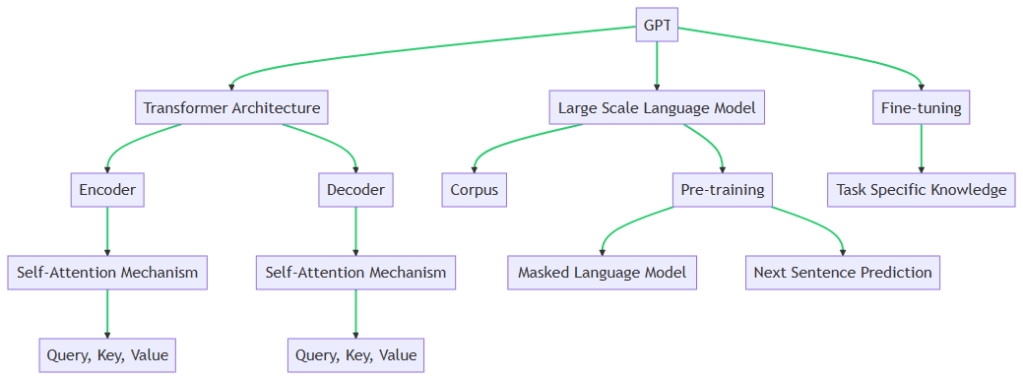
The key GPT (Generative Pretrained Transformer) concepts start with Transformer Architecture, Large Scale Language Models, and Fine-tuning.
Transformer Architecture
The Transformer architecture is a type of model architecture used in natural language processing tasks. It was introduced in the paper “Attention is All You Need” by Vaswani et al (https://arxiv.org/abs/1706.03762). The key innovation of the Transformer is the self-attention mechanism, which allows the model to weigh the importance of words in an input sequence when generating an output sequence. This is particularly useful in tasks like machine translation, where the relevance of a word can depend on its context in the sentence. The Transformer architecture consists of an encoder and a decoder. Each of these is composed of a stack of identical layers, with each layer having two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network. The Encoder uses a Self-Attention Mechanism, which operates on Query, Key, and Value representations of the input. The Decoder also uses a Self-Attention Mechanism, with its own Query, Key, and Value representations.
Self-Attention Mechanism
Step 1 – Embedding the Input: This step involves matrix multiplication. Each word in the input sequence is represented as a vector (word embedding). This vector is then multiplied by three separate weight matrices that the model learns during training, resulting in Query (Q), Key (K), and Value (V) vectors for each word.
Step 2 – Calculating Attention Scores: This step involves the dot product operation. The dot product is taken between the Query vector for a particular word and the Key vector for every other word in the sequence. This results in a score that represents the compatibility between the word we’re focusing on and every other word.
Step 3 – Softmaxing Attention Scores: This step involves the softmax function, which is a type of exponential function. The softmax function is applied to the attention scores from the previous step, converting them into probabilities that sum to 1. This ensures that the highest score will have the highest probability, and that all the scores are in the range (0,1).
Step 4 – Creating the Output: This step involves multiplication and summation. The softmaxed attention scores are multiplied by their respective Value vectors (this is element-wise multiplication). The results are then summed to produce the final output vector. This output vector is a weighted sum of all the Value vectors, where the weights are the softmaxed attention scores.
Large Scale Language Models
Large scale language models like GPT are trained on a large corpus of text data. These models learn to predict the next word in a sentence, which allows them to generate human-like text. The training process involves feeding the model billions of sentences and adjusting the model’s parameters to minimize the difference between its predictions and the actual next words in the sentences. This process allows the model to learn the statistical patterns of the language, such as grammar, facts about the world, and even some reasoning abilities. However, because these models learn from the data they are trained on, they can also pick up biases present in the data.
Pre-Training Phase
The pre-training phase involves a Masked Language Model and Next Sentence Prediction tasks. However, it’s important to note that GPT specifically uses a variant of the Masked Language Model task but does not use the Next Sentence Prediction task. These two tasks are actually more associated with BERT, another transformer-based model.
Masked Language Model (MLM)
In the Masked Language Model task, some percentage of the input data is masked or hidden from the model. For example, in the sentence “The cat sat on the mat”, one or more words might be replaced with a [MASK] token, like “The cat sat on the [MASK]”. The model’s task is to predict the masked words based only on the context provided by the unmasked words. This forces the model to learn to understand the context in which words are used. In the case of GPT, it uses a variant of this task where it predicts every next word in a sentence given the previous words (autoregressive language modeling), rather than predicting masked words.
Next Sentence Prediction (NSP)
In the Next Sentence Prediction task, the model is given pairs of sentences and has to predict whether the second sentence in the pair is the subsequent sentence in the original document. For example, given the two sentences “I love to play football. I had pasta for dinner.”, the model should predict that the second sentence is not the next sentence of the first one in their original context. This task helps the model understand the relationships between sentences.
The pre-training phase involves training the model on a large corpus of text with these tasks. The model learns to understand the syntax and semantics of the language, as well as some world facts and reasoning abilities. After this phase, the model can generate plausible-sounding text, but it’s not yet specialized for any specific task. That’s where the fine-tuning phase comes in, which involves further training the model on a smaller, task-specific dataset.
Addressing LLM Bias
Avoiding biases in large scale language models is a complex task due to the nature of the data they are trained on. These models learn from vast amounts of text data, which can include biases present in those texts. However, there are several strategies that can help mitigate these biases:
Curate Training Data
One of the most effective ways to avoid biases is to carefully curate the training data. This involves removing or minimizing data that contains biased or offensive content. However, this can be a challenging and resource-intensive task given the vast amounts of data used to train these models.
Bias Mitigation Techniques
Techniques such as counterfactual data augmentation, where the training data is augmented with examples that counteract existing biases, can be used. Another technique is bias-specific fine-tuning, where the model is fine-tuned on a dataset specifically designed to reduce certain biases.
Fairness Metrics
Incorporate fairness metrics into the model evaluation process. These metrics can help quantify the extent of bias in model predictions and can be used alongside traditional performance metrics to guide model development.
Transparency and Interpretability
Making the model’s decision-making process more transparent can help identify when and where biases occur. Techniques for improving model interpretability can be useful in this regard.
Diverse Development Team
Having a diverse team of people involved in the development and review process can help ensure a variety of perspectives are considered, which can help in identifying and mitigating biases.
Continuous Monitoring
Even after deployment, models should be continuously monitored for biased behavior. User feedback can be a valuable resource for identifying biases that were not caught during development.
Ethics Training
Providing ethics training for data scientists and engineers involved in developing these models can also be beneficial. This can help them understand the potential societal impacts of biased AI systems and the importance of mitigating these biases.
It’s important to note that completely eliminating biases in large scale language models is currently an open research problem, and these strategies can only help mitigate, not completely eliminate, these biases.
Fine-tuning
After the initial pre-training phase, GPT models are fine-tuned for specific tasks. This involves continuing the training process with a smaller, task-specific dataset. The fine-tuning process allows the model to adapt its general language understanding abilities to the specific requirements of the task. For example, if the task is to answer questions about medical texts, the fine-tuning process would involve training the model on a dataset of medical question-answer pairs. This allows the model to learn the specific language and knowledge required for the task.
Task-Specific Data
The first step in fine-tuning is to gather a dataset that is specific to the task the model will be performing. For example, if the task is question answering, the dataset would consist of question-answer pairs. The size of this dataset is typically much smaller than the corpus used for pre-training.
Adapting the Model
The model is then trained on this task-specific dataset. However, instead of starting the training process from scratch, the model starts with the weights it learned during pre-training. This is why it’s called “fine-tuning” – the model is adjusting the general language understanding it learned during pre-training to the specifics of the task.
Learning Rate
During fine-tuning, a lower learning rate is typically used compared to the pre-training phase. This is because the model has already learned general language features during pre-training, and we don’t want to drastically change those weights. Instead, we want to make smaller adjustments to adapt to the task-specific data.
Evaluation
After fine-tuning, the model is evaluated on a separate test set to assess its performance on the task. If the performance is not satisfactory, adjustments can be made to the fine-tuning process (like gathering more task-specific data or adjusting the learning rate) and the model can be fine-tuned again.
These concepts are fundamental to the operation of GPT and other similar models. They allow the model to understand and generate human-like text and adapt to a wide variety of tasks. While this is a simplification, it provides a high-level overview of how GPT and GPT like models work. For a more detailed understanding, I would recommend looking into papers and resources on Transformer-based models and self-attention mechanisms. Here are some references for understanding more about GPT and Transformer models:
- The original paper on Transformer models, “Attention is All You Need” by Vaswani et al., introduced the concept of attention mechanisms as the primary component in state-of-the-art language models. You can access the paper here: https://arxiv.org/abs/1706.03762
- The “GPT-2: Language Models are Unsupervised Multitask Learners” paper by Radford et al. explains the specifics of the GPT-2 model, which is the predecessor to GPT-3. It can be found here: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- The Illustrated Transformer by Jay Alammar is a blog post providing a visual and intuitive understanding of how Transformer models work. It can be found here: http://jalammar.github.io/illustrated-transformer/
- The Illustrated GPT-2, also by Jay Alammar, is a blog post that builds on the previous one by explaining how the GPT-2 model specifically uses Transformer architecture. It can be found here: http://jalammar.github.io/illustrated-gpt2/
- The “GPT-3: Language Models are Few-Shot Learners” paper by Brown et al. provides an overview of GPT-3, the model that ChatGPT is based on. The paper can be accessed here: https://arxiv.org/abs/2005.14165
Please note that these resources have a range of technical levels, so some may be more accessible depending on your background in machine learning and natural language processing.
